Where we left off
In the previous post we’ve gone through setting up the microphone capture and getting a steady stream of raw Vec<f32> audio data. We also handled some errors and set up a nice pipelined system for handling the different steps in our processing pipeline.
Goal of this post

The goal of this post is to take the raw microphone input and do some basic processing of it. In particular we want to split the stream into chunks and perform a voice activity detection. What that means is we’ll detect when there is acual sound being received and ignore the silence (which still produces audio data). We’ll then capture a raw block of audio that has some voice activity in it and send it along for processing.
While the underlying mechanism involves a fair amount of math to figure out this post should be relatively short and easy to follow.
What is VAD?
Voice Activity Detection or VAD for short is the detection of the presence of speech. In our case it’s very useful because it allows us to start filtering useful audio input from noise and garbage. It’s quite simple for a human to figre out which parts of this waveform might have something useful in them for example.
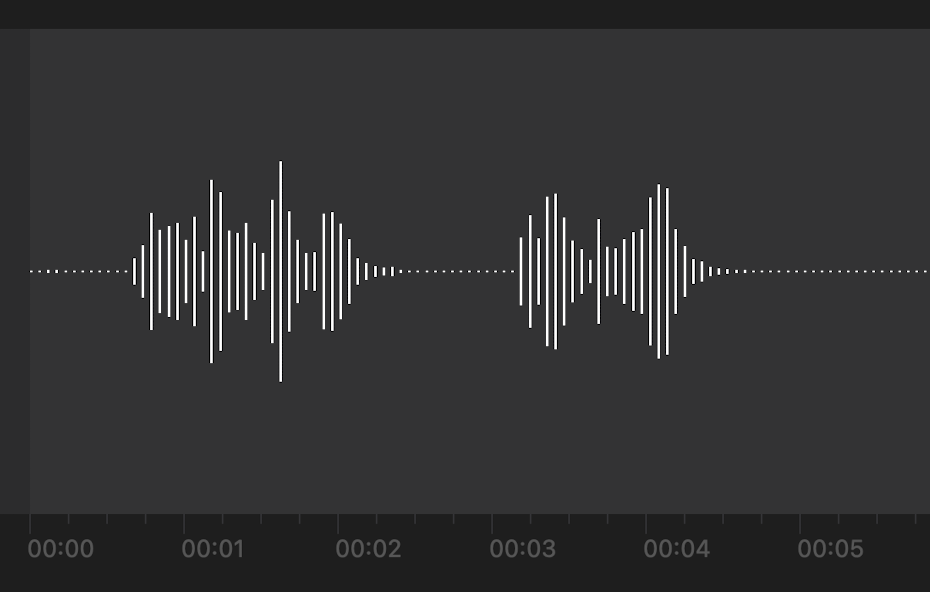
It’s not hard to see there’s something going on from ~0.6s until ~2.5s and again from ~3.1s until ~4.5s. Even though it might not be so intuitive for a computer we can still figure out what data to use pretty easily for our purposes. We’ll do that by using VAD.
A simple VAD approach
In pseudocode our VAD algorithm will work as follows:
- Break the continuous stream of data apart into small chunks
- Calculate the audio energy of the chunk
- If it's less than a predetermined threshold discard it
- If it's more append it to a buffer
- Keep appending until there's X empty chunks again
- Flush the buffer into the next stage of the pipeline
Effectively it means removing all the silence and grouping together the bits in which audio activity is happening. One thing we could do additionally is that we could look at what frequences are present and add some more filitering to only use bits in which human speech is likely to occur. But we’ll defer this bit to the STT (speech to text) library and make sure it’s intelligible there.
Coding VAD
Now honestly I don’t think it makes sense to go through VAD bit by bit so I’ll just paste the whole processing/vad_chunker.rs file here and add some explanation in the comments. It’s the append a particular kind of samples to a buffer and when a condition X is met flush the buffer kind of engineering problem and is quite prevalent. Only special thing here is calculating the energy of an audio chunk but even that sounds fancier than it actually is.
use std::{mem::take, sync::mpsc::{Receiver, Sender}};
// Again we use the constant which is 16k samples
use crate::core::constants::MIC_SAMPLE_RATE;
// Processing 20ms of audio at a time (20 / 1000)
const WINDOW_SIZE: f32 = 20f32 / 1000f32;
// Number of samples per window
const FRAME_SIZE: usize = (MIC_SAMPLE_RATE as f32 * WINDOW_SIZE) as usize;
// How loud it should be before we start including data for
// the next step of the pipeline. This should be modified for
// different setups.
const SPEECH_ENERGY_THRESHOLD: f32 = 0.01;
// How much blank time we allow in between speech pauses
// This controls how long pauses in the speech can be for us
// to flush the buffer and start the new one.
// 15 * 20ms = 300ms so we allow the speaker about 0.3s of silence
// with this config value. Probably not ideal.
const EMPTY_FRAMES_PROCESS_THRESHOLD: i32 = 15;
// We have an upper limit on how long we'll listen for.
// Otherwise if the mic is in a noisy environment we'll
// keep appending the data and never flush. At a 20ms
// frame this is 20s right now.
const MAX_BUFFER_SIZE: usize = FRAME_SIZE * 1000;
// The main func of the vad_chunker
// Takes the Receiver of the previous stage (mic_input.rs)
// And sends out the same data via Sender but nicely split apart
// so that it can be processed further
pub fn main(mic_rx: Receiver<Vec<f32>>, chunker_tx: Sender<Vec<f32>>) {
// Data into which the incoming mic_rx stream is appended
let mut data = Vec::<f32>::new();
// The buffer we use to fill with actual useful audio data
// and that is then flushed through chunker_tx
let mut speech_data = Vec::<f32>::new();
// Empty frame counter for comparing to the threshold
let mut empty_frames = 0;
// The main loop of the chunker
// work while the channel can receive data
while let Ok(partial) = mic_rx.recv() {
// Add to the stream
data.append(&mut partial);
// Process in a FIFO fashion. While there is data
// to be processed (at least 20ms worth of audio)
while data.len() > FRAME_SIZE {
// Take out the amount of samples
let mut frame: Vec<f32> = data.drain(0..FRAME_SIZE).collect();
// And calculate its energy
let frame_energy = frame_energy(&frame);
// If you're curious what that looks like
// this will show you
println!("Frame energy {}", frame_energy);
// Is the energy in this frame high enough
if frame_energy > SPEECH_ENERGY_THRESHOLD {
speech_data.append(&mut frame); // Append to the output buffer
// If there's too much data in the buffer
// we flush it
if speech_data.len() >= MAX_BUFFER_SIZE {
if chunker_tx.send(take(&mut speech_data)).is_err() {
break // If send fails the channel is broken
}
}
//Otherwise energy is <= the threshold, we discard the sample
} else if !speech_data.is_empty() { // But first we check if we have anything useful in the `speech_data` buffer
// This is another empty frame
empty_frames += 1;
// If amount of blank audio is still under the
// 0.3s threshold we keep going cause the speaker
// might have had a short pause
if empty_frames < EMPTY_FRAMES_PROCESS_THRESHOLD {
continue
}
// Otherwise flush the buffer for the next step of the pipeline
if chunker_tx.send(take(&mut speech_data)).is_err() {
break // If send fails the channel is broken
}
}
}
}
}
// Extracted into a separate function as we could do additional logic here
// Here's an excellent resource for more VAD insight:
// https://speechprocessingbook.aalto.fi/Recognition/Voice_activity_detection.html
fn frame_energy(frame: &Vec<f32>) -> f32 {
// Right now we just square all of the values and sum them together
frame.iter().map(|val| val * val).sum::<f32>()
}
There might be more comments explaining the code than actual code. That’s how simple our VAD algoritm is. The last thing to do is to integrate it back into our main.rs. Let’s do that next:
let (chunker_tx, chunker_rx) = channel::<Vec<f32>>();
thread_pool.spawn(async move {
processing::vad_chunker::main(mic_rx, chunker_tx);
println!("VAD chunker shutting down");
});
Notice we don’t create any signals or anything since there’s nothing that can really go wrong in here. It’s just some math and buffering. If the microphone before this step breaks down we’ll know and our mic_rx will give us an error upon recv() which will in turn break out of the main loop and conclude VAD chunker’s main as well.
I know I’m not including any examples of how it looks like to run this code. But I’ll leave a piece of the magic of making something work to you dear reader. After all when you write some code yourself, test it and it works it feels amazing.
That’s all there is to it with this post. Next up we’ll take a look at how to do some more filtering and only awake when a wake word is used.